假如执行 kubectl create deployment nginx --image=nginx --replicas=3 命令,背后发生了什么(基于 Kubernetes v1.21.0)

Kubectl #
校验 #
首先 Kubectl 会执行客户端验证,以确保非法的请求(例如,创建不支持的资源或使用格式错误的镜像名称)快速失败,并不会发送给 kube-apiserver。
Kubectl 还将确定是否需要触发其他操作,例如记录(record)命令(用于部署或审计),或者此命令是否是 dry run。
创建 HTTP 请求 #
验证通过后, Kubectl 开始构造它将发送给 kube-apiserver 的 HTTP 请求。在 Kubernetes 中,访问或更改状态的所有尝试都通过 kube-apiserver 进行,后者又与 etcd 进行通信。
创建 HTTP 请求用到了所谓的 generator ,它封装了资源的序列化(serialization)操作。每个 generator 都实现了一个 Generate() 方法,用于生成一个该资源的运行时对象(runtime object)
客户端认证 #
客户端通过 kubeconfig 文件,进行集群、用户认证,组装出 HTTP 请求的认证头。支持几种认证方式
- X509 证书:放到 TLS 中发送;
- Bearer token:放到 HTTP “Authorization” 头中 发送;
- 用户名密码:放到 HTTP basic auth 发送;
- OpenID Connect (OIDC) 认证(例如和外部的 Keystone、Google 账号打通):需要先由用户手动处理,将其转成一个 token,然后和 bearer token 类似发送。
版本协商 #
生成 runtime object 之后,kubectl 开始搜索合适的 API Group、版本。然后创建一个正确版本的客户端(versioned client)。
// staging/src/k8s.io/kubectl/pkg/cmd/run/run.go
obj := generator.Generate(params) // 创建运行时对象
mapper := f.ToRESTMapper() // 寻找适合这个资源(对象)的 API group
以上就是版本协商的过程。实现上,kubectl 会 扫描 kube-apiserver 的 /apis 路径 (OpenAPI 格式的 schema 文档),获取所有的 API groups。出于性能考虑,kubectl 会 缓存 这份 OpenAPI schema, 路径是 ~/.kube/cache/discovery。想查看这个 API discovery 过程,可以删除这个文件, 然后随便执行一条 kubectl 命令,并指定足够大的日志级别(例如 kubectl get ds -v 10)。
最后将请求发送出去
kube-apiserver #
请求从客户端发出后,便来了 kube-apiserver。
认证 #
kube-apiserver 首先会对请求进行认证(authentication),以确保用户身份是合法的(verify that the requester is who they say they are)。
- x509 handler 验证该 HTTP 请求是用 TLS key 加密的,并且有 CA root 证书的签名。
- bearer token handler 验证请求中带的 token(HTTP Authorization 头中),在 apiserver 的 auth file 中是存在的(–token-auth-file)。
- basicauth handler 对 basic auth 信息进行校验。
认证成功后,会将 Authorization header 从请求中删除,然后在 context 中加上用户信息, 后面的步骤(例如鉴权和 admission control)便可以从 context 中提取用户身份信息。
func withAuthentication(handler http.Handler, auth authenticator.Request, failed http.Handler, apiAuds authenticator.Audiences, metrics recordMetrics) http.Handler {
...
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
...
resp, ok, err := auth.AuthenticateRequest(req) // 遍历所有 authenticator,任何一个成功就返回 OK
...
if err != nil || !ok {
if err != nil {
klog.ErrorS(err, "Unable to authenticate the request")
}
failed.ServeHTTP(w, req)
return
}
if !audiencesAreAcceptable(apiAuds, resp.Audiences) {
err = fmt.Errorf("unable to match the audience: %v , accepted: %v", resp.Audiences, apiAuds)
klog.Error(err)
failed.ServeHTTP(w, req)
return
}
// authorization header is not required anymore in case of a successful authentication.
req.Header.Del("Authorization")
req = req.WithContext(genericapirequest.WithUser(req.Context(), resp.User)) // 将用户信息放到 context 中
handler.ServeHTTP(w, req)
})
}
鉴权(Authorization) #
确认发送者身份之后,接下来进行鉴权。鉴权的过程与认证相似,即逐个匹配 authorizer 列表中的 authorizer。如果都失败了则返回 Forbidden。
内置的 几种 authorizer 类型:
- webhook: 与其他服务交互,验证是否有权限。
- ABAC: 根据静态文件中规定的策略(policies)来进行鉴权。
- RBAC: 根据 role 进行鉴权,其中 role 是 k8s 管理员提前配置的。
- Node: 确保 node clients,例如 kubelet,只能访问本机内的资源。
鉴权细节实现在 Authorize() 方法中。
准入控制器(Admission Controller) #
K8s 中的其它组件还需要对请求进行检查,其中就包括 admission controllers。
与鉴权的区别 鉴权(authorization)在前面,关注的是用户是否有操作权限,而 Admission controllers 在更后面,对请求进行拦截和过滤,确保它们符合一些更广泛的集群规则和限制,是将请求对象持久化到 etcd 之前的最后堡垒。
工作方式也是进行遍历列表,如果出现任何一个 controller 检查不通过,则请求失败
每个 controller 作为一个 plugin 存放在 plugin/pkg/admission 目录,需要实现几个特定接口,最终编译到 k8s 的二进制文件。
Admission controllers 按不同目的分类,可分为:资源管理、安全管理、默认值管理、引用一致性(referential consistency)等类型。
例如,如下面是资源管理类的几个 controller:
- InitialResources:为容器设置默认的资源限制(基于过去的使用量);
- LimitRanger:为容器的 requests and limits 设置默认值,或对特定资源设置上限(例如,内存默认 512MB,最高不超过 2GB)。
- ResourceQuota:资源配额。
写入 ETCD #
kube-apiserver 将对请求进行反序列化,构造 runtime objects( kubectl generator 的反过程),并将它们持久化到 etcd。
源码位置:
registerResourceHandlers // staging/src/k8s.io/apiserver/pkg/endpoints/installer.go
|-case POST:
从 apiserver 的请求处理函数开始:
// staging/src/k8s.io/apiserver/pkg/server/handler.go
func (d director) ServeHTTP(w http.ResponseWriter, req *http.Request) {
path := req.URL.Path
// check to see if our webservices want to claim this path
for _, ws := range d.goRestfulContainer.RegisteredWebServices() {
switch {
case ws.RootPath() == "/apis":
if path == "/apis" || path == "/apis/" {
return d.goRestfulContainer.Dispatch(w, req)
}
case strings.HasPrefix(path, ws.RootPath()):
if len(path) == len(ws.RootPath()) || path[len(ws.RootPath())] == '/' {
return d.goRestfulContainer.Dispatch(w, req)
}
}
}
// if we didn't find a match, then we just skip gorestful altogether
d.nonGoRestfulMux.ServeHTTP(w, req)
}
如果能匹配到请求(例如匹配到前面注册的路由),它将分派给相应的 handler ;否则,fall back 到 path-based handler (GET /apis 到达的就是这里);
基于 path 的 handlers:
// staging/src/k8s.io/apiserver/pkg/server/mux/pathrecorder.go
func (h *pathHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if exactHandler, ok := h.pathToHandler[r.URL.Path]; ok {
return exactHandler.ServeHTTP(w, r)
}
for prefixHandler := range h.prefixHandlers {
if strings.HasPrefix(r.URL.Path, prefixHandler.prefix) {
return prefixHandler.handler.ServeHTTP(w, r)
}
}
h.notFoundHandler.ServeHTTP(w, r)
}
如果还是没有找到路由,就会 fallback 到 non-gorestful handler,最终可能是一个 not found handler。对于 pod 创建场景,会匹配到一条已经注册的、名为 createHandler 为的路由。
Create handler 处理 #
// staging/src/k8s.io/apiserver/pkg/endpoints/handlers/create.go
func createHandler(r rest.NamedCreater, scope *RequestScope, admit Interface, includeName bool) http.HandlerFunc {
return func(w http.ResponseWriter, req *http.Request) {
namespace, name := scope.Namer.Name(req) // 获取资源的 namespace 和 name(etcd item key)
s := negotiation.NegotiateInputSerializer(req, false, scope.Serializer)
body := limitedReadBody(req, scope.MaxRequestBodyBytes)
obj, gvk := decoder.Decode(body, &defaultGVK, original)
admit = admission.WithAudit(admit, ae)
requestFunc := func() (runtime.Object, error) {
return r.Create(
name,
obj,
rest.AdmissionToValidateObjectFunc(admit, admissionAttributes, scope),
)
}
result := finishRequest(ctx, func() (runtime.Object, error) {
if scope.FieldManager != nil {
liveObj := scope.Creater.New(scope.Kind)
obj = scope.FieldManager.UpdateNoErrors(liveObj, obj, managerOrUserAgent(options.FieldManager, req.UserAgent()))
admit = fieldmanager.NewManagedFieldsValidatingAdmissionController(admit)
}
admit.(admission.MutationInterface)
mutatingAdmission.Handles(admission.Create)
mutatingAdmission.Admit(ctx, admissionAttributes, scope)
return requestFunc()
})
code := http.StatusCreated
status, ok := result.(*metav1.Status)
transformResponseObject(ctx, scope, trace, req, w, code, outputMediaType, result)
}
}
-
首先解析 HTTP request,然后执行基本的验证,例如保证 JSON 与 versioned API resource 期望的是一致的;
-
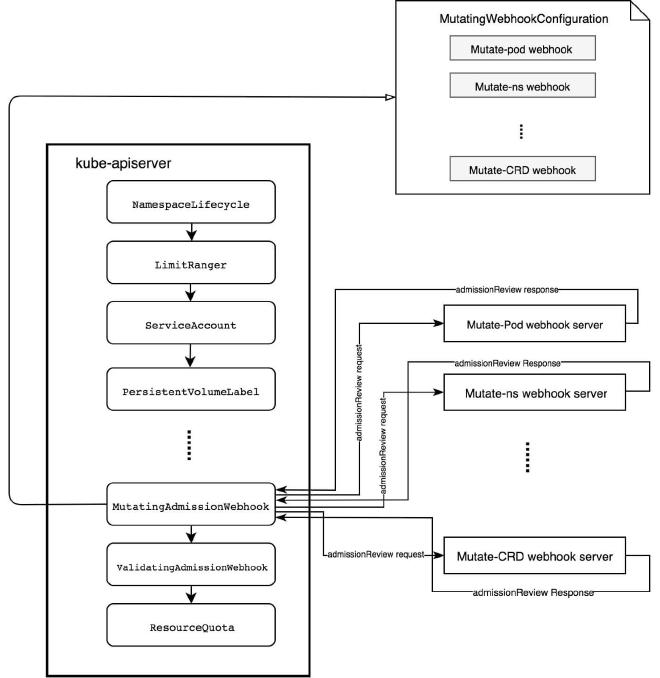
执行审计和最终 admission; 这里会执行所谓的 Mutation 操作,例如,如果 pod 打了 sidecar-injector-webhook.xxx/inject: true 标签,并且配置了合适的 Mutation webhook 和 server, 在这一步就会给它自动注入 sidecar,完整例子可参考 Diving into Kubernetes MutatingAdmissionWebhook。
-
将资源最终写到 etcd, 这会进一步调用到 storage provider。
etcd key 的格式一般是
<namespace>/<name>(例如,default/nginx-0),但这个也是可配置的。 -
最后,storage provider 执行一次 get 操作,确保对象真的创建成功了。如果有额外的收尾任务(additional finalization),会执行 post-create handlers 和 decorators。
-
生成 HTTP response 并返回。
另外,kube-apiserver 通过 ListWatch 监听了 etcd 的 pod 资源,因此 etcd 创建 pod 成功之后, kube-apiserver 会收到 create 事件,将 pod 信息更新到它的 in-memory cache 里。
至此我们的 pod 资源已经在 etcd 中了。但是,此时 kubectl get pods -n <ns> 还看不见它。
Initializers #
Initializer 是与特定资源类型(resource type)相关的 controller,负责在该资源对外可见之前对它们执行一些处理。如果一种资源类型没有注册任何 initializer,这个步骤就会跳过,资源对外立即可见。
这是一种非常强大的特性,使得我们能执行一些通用的启动初始化(bootstrap)操作。例如,
- 向 Pod 注入 sidecar、暴露 80 端口,或打上特定的 annotation。
- 向某个 namespace 内的所有 pod 注入一个存放了测试证书(test certificates)的 volume。
- 禁止创建长度小于 20 个字符的 Secret (例如密码)。
InitializerConfiguration #
可以用 InitializerConfiguration 声明对哪些资源类型(resource type)执行哪些 initializer。
例如,要实现所有 pod 创建时都运行一个自定义的 initializer custom-pod-initializer, 可以用下面的 yaml:
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: InitializerConfiguration
metadata:
name: custom-pod-initializer
initializers:
- name: podimage.example.com
rules:
- apiGroups:
- ""
apiVersions:
- v1
resources:
- pods
创建以上配置(kubectl create -f xx.yaml)之后,K8s 会将 custom-pod-initializer 追加到每个 pod 的 metadata.initializers.pending 字段。
在此之前需要启动 initializer controller,它会
- 定期扫描是否有新 pod 创建;
- 当检测到它的名字出现在 pod 的 pending 字段时,就会执行它的处理逻辑;
- 执行完成之后,它会将自己的名字从 pending list 中移除。
pending list 中的 initializers,每次只有第一个 initializer 能执行。 当所有 initializer 执行完成,pending 字段为空之后,就认为 这个对象已经完成初始化了(considered initialized)。
前面说这个对象还没有对外可见,那用户空间的 initializer controller 又是如何能检测并操作这个对象的呢?答案是:kube-apiserver 提供了一个
?includeUninitialized查询参数,它会返回所有对象,包括那些还未完成初始化的(uninitialized ones)。
Control loops(控制循环) #
对象已经存储在了 etcd 中,所有的初始化步骤也已经完成了。 下一步是设置资源拓扑(resource topology)。例如,一个 Deployment 其实就是一组 ReplicaSet,而一个 ReplicaSet 就是一组 Pod。 K8s 是如何根据一个 HTTP 请求创建出这个层级关系的呢?靠的是 K8s 内置的控制器(controllers)。
K8s 中大量使用 “controllers”,
controller 可以理解成一个异步脚本(an asynchronous script),不断检查资源的当前状态(current state)和期望状态(desired state)是否一致,如果不一致就尝试将其变成期望状态,这个过程称为 reconcile。所有 controller 并发运行, 由 kube-controller-manager 统一管理。
当一个 Deployment record 存储到 etcd 并(被 initializers)初始化之后,kube-apiserver 就会将其置为对外可见的。此后,Deployment controller 监听了 Deployment 资源的变动,此时就会检测到这个新创建的资源。
在本文场景中,触发的是 controller 注册的 addDeployment() 回调函数 其所做的工作就是将 deployment 对象放到一个内部队列。worker 不断遍历这个 queue,从中 dequeue item 并进行处理:
// pkg/controller/deployment/deployment_controller.go
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() {
}
}
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get()
dc.syncHandler(key.(string)) // dc.syncHandler = dc.syncDeployment
}
// syncDeployment will sync the deployment with the given key.
func (dc *DeploymentController) syncDeployment(key string) error {
namespace, name := cache.SplitMetaNamespaceKey(key)
deployment := dc.dLister.Deployments(namespace).Get(name)
d := deployment.DeepCopy()
// 获取这个 Deployment 的所有 ReplicaSets, while reconciling ControllerRef through adoption/orphaning.
rsList := dc.getReplicaSetsForDeployment(d)
// 获取这个 Deployment 的所有 pods, grouped by their ReplicaSet
podMap := dc.getPodMapForDeployment(d, rsList)
if d.DeletionTimestamp != nil { // 这个 Deployment 已经被标记,等待被删除
return dc.syncStatusOnly(d, rsList)
}
dc.checkPausedConditions(d)
if d.Spec.Paused { // pause 状态
return dc.sync(d, rsList)
}
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
scalingEvent := dc.isScalingEvent(d, rsList)
if scalingEvent {
return dc.sync(d, rsList)
}
switch d.Spec.Strategy.Type {
case RecreateDeploymentStrategyType: // re-create
return dc.rolloutRecreate(d, rsList, podMap)
case RollingUpdateDeploymentStrategyType: // rolling-update
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
controller 会通过 label selector 从 kube-apiserver 查询 与这个 deployment 关联的 ReplicaSet 或 Pod records(然后发现没有)。
如果发现当前状态与预期状态不一致,就会触发同步过程(synchronization process)。 这个同步过程是无状态的,也就是说,它并不区分是新记录还是老记录,一视同仁。
执行扩容 #
当发现 pod 不存在之后,它会开始扩容过程(scaling process):
// pkg/controller/deployment/sync.go
// scale up/down 或新创建(pause)时都会执行到这里
func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, oldRSs := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
dc.scale(d, newRS, oldRSs)
// Clean up the deployment when it's paused and no rollback is in flight.
if d.Spec.Paused && getRollbackTo(d) == nil {
dc.cleanupDeployment(oldRSs, d)
}
allRSs := append(oldRSs, newRS)
return dc.syncDeploymentStatus(allRSs, newRS, d)
}
大致步骤:
- Rolling out(例如 creating)一个 ReplicaSet resource
- 分配一个 label selector
- 初始版本号(revision number)置为 1
ReplicaSet 的 PodSpec,以及其他一些 metadata 是从 Deployment 的 manifest 拷过来的。
最后会更新 deployment 状态,然后重新进入 reconciliation 循环,直到 deployment 进入预期的状态。
ReplicaSets controller #
ReplicaSet controller 任务是监控 ReplicaSet 及其依赖资源(pods)的生命周期,实现方式也是注册事件回调函数。
当一个 ReplicaSet 被(Deployment controller)创建之后,RS controller 检查 ReplicaSet 的状态,发现当前状态和期望状态之间有偏差,接下来调用 manageReplicas() 来 reconcile 这个状态,增加这个 ReplicaSet 的 pod 数量。
// pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) manageReplicas(filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
rsKey := controller.KeyFunc(rs)
if diff < 0 {
diff *= -1
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
rsc.expectations.ExpectCreations(rsKey, diff)
successfulCreations := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() {
return rsc.podControl.CreatePodsWithControllerRef( // 扩容
// 调用栈 CreatePodsWithControllerRef -> createPod() -> Client.CoreV1().Pods().Create()
rs.Namespace, &rs.Spec.Template, rs, metav1.NewControllerRef(rs, rsc.GroupVersionKind))
})
// The skipped pods will be retried later. The next controller resync will retry the slow start process.
if skippedPods := diff - successfulCreations; skippedPods > 0 {
for i := 0; i < skippedPods; i++ {
// Decrement the expected number of creates because the informer won't observe this pod
rsc.expectations.CreationObserved(rsKey)
}
}
return err
} else if diff > 0 {
// 增加 pod 数量的操作每次最多不超过 burst count,这个配置从 父对象 Deployment 继承
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
relatedPods := rsc.getIndirectlyRelatedPods(rs)
podsToDelete := getPodsToDelete(filteredPods, relatedPods, diff)
rsc.expectations.ExpectDeletions(rsKey, getPodKeys(podsToDelete))
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
rsc.podControl.DeletePod(rs.Namespace, targetPod.Name, rs) // 缩容
}(pod)
}
}
return nil
}
创建 Pod 的过程是慢启动的,最开始是 SlowStartInitialBatchSize,每执行成功一批后,下一批数量翻倍,减少给 kube-apiserver 压力。如果 quto 不足创建失败,也只有一小批次会请求到 kube-apiserver 返回失败。
Owner reference #
K8s 通过 Owner Reference(子资源中的一个字段,指向的是其父资源的 ID) 维护对象层级(hierarchy)。这可以带来两方面好处:
- 实现了 cascading deletion,即父对象被 GC 时会确保 GC 子对象;
- 父对象之间不会出现竞争子对象的情况(例如,两个父对象认为某个子对象都是自己的)
另一个隐藏的好处是:Owner Reference 是有状态的:如果 controller 重启,重启期间不会影响系统的其他部分,因为资源拓扑(resource topology)是独立于 controller 的。 这种隔离设计也体现在 controller 自己的设计中:controller 不应该操作其他 controller 的资源(resources they don’t explicitly own)。
有时也可能会出现“孤儿”资源(”orphaned” resources)的情况,例如
- 父资源删除了,子资源还在;
- GC 策略导致子资源无法被删除。
这种情况发生时,controller 会确保孤儿资源会被某个新的父资源收养。 多个父资源都可以竞争成为孤儿资源的父资源,但只有一个会成功(其余的会收到一个 validation 错误)。
Informers #
很多 controller(例如 RBAC authorizer 或 Deployment controller)需要将集群信息拉到本地。
例如 RBAC authorizer 中,authenticator 会将用户信息保存到请求上下文中。随后, RBAC authorizer 会用这个信息获取 ETCD 中所有与这个用户相关的 role 和 role bindings。
那么,controller 是如何访问和修改这些资源的?在 K8s 中,这是通过 informer 机制实现的。
informer 是一种 controller 订阅存储(etcd)事件的机制,能方便地获取它们感兴趣的资源。
这种方式除了提供一种很好的抽象之外,还负责处理缓存(caching,非常重要,因为可以减少 kube-apiserver 连接数,降低 controller 侧和 kube-apiserver 侧的序列化 成本)问题。
此外,这种设计还使得 controller 的行为是 threadsafe 的,避免影响其他组件或服务。
Scheduler(调度器) #
以上 controllers 执行完各自的处理之后,etcd 中已经有了一个 Deployment、一个 ReplicaSet 和三个 Pods,可以通过 kube-apiserver 查询到。
但此时,这三个 pod 还在 Pending 状态,因为它们还没有被调度到任何节点。 另外一个 controller 即 调度器 负责做这件事情。
scheduler 作为控制平面的一个独立服务运行,但工作方式与其他 controller 是一样的: 监听事件,然后尝试 reconcile 状态。作为一个无限循环,scheduler 会寻找所有 nodeName 字段为空的 pod,为它们选择合适的 node,这就是调度过程(nodeName 不为空的 pod 会直接调度到指定 nodeName 的节点上)。
scheduler 筛选 Nodes 列表,如果 pod.Spec 中配置了资源的 request,那么无法满足的 node 会从列表中被删除。scheduler 会执行注册的过滤策略。
// pkg/scheduler/algorithmprovider/registry.go
// NewRegistry returns an algorithm provider registry instance.
func NewRegistry() Registry {
defaultConfig := getDefaultConfig()
applyFeatureGates(defaultConfig)
caConfig := getClusterAutoscalerConfig()
applyFeatureGates(caConfig)
return Registry{
schedulerapi.SchedulerDefaultProviderName: defaultConfig,
ClusterAutoscalerProvider: caConfig,
}
}
func getDefaultConfig() *schedulerapi.Plugins {
plugins := &schedulerapi.Plugins{
PreFilter: schedulerapi.PluginSet{...},
Filter: schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodename.Name}, // 指定 node name 调度
{Name: tainttoleration.Name}, // 指定 toleration 调度
{Name: nodeaffinity.Name}, // 指定 node affinity 调度
...
},
},
PostFilter: schedulerapi.PluginSet{...},
PreScore: schedulerapi.PluginSet{...},
Score: schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: interpodaffinity.Name, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: tainttoleration.Name, Weight: 1},
...
},
},
Reserve: schedulerapi.PluginSet{...},
PreBind: schedulerapi.PluginSet{...},
Bind: schedulerapi.PluginSet{...},
}
return plugins
}
筛选出满足过滤条件的 Node 之后,接下来会执行一系列 priority function 对这些 nodes 进行排序。 例如,如果算法是希望将 pods 尽量分散到整个集群,那 priority 会选择资源尽量空闲的节点。prioritizeNodes() 函数会给每个 node 打分,得分最高的 node 会被选中,调度到该节点。
算法选出一个 node 之后,调度器会创建一个 Binding 对象, Pod 的 ObjectReference 字段的值就是选中的 node 的名字。最后通过 Post 请求发送给 kube-apiserver。
kube-apiserver 收到这个 Binding object 请求后,registry 反序列化对象,更新 Pod 对象的下列字段:
- 设置 NodeName
- 添加 annotations
- 设置 PodScheduled status 为 True
predicate 和 priority function 都是可扩展的,可以通过 –policy-config-file 指定。K8s 还可以自定义调度器(自己实现调度逻辑)。 如果 PodSpec 中 schedulerName 字段不为空,K8s 就会将这个 pod 的调度权交给指定的调度器。
目前为止,我们看到的所有东西(状态),还只是存在于 etcd 中的元数据。 下一步就是将这些状态同步到计算节点上,然后计算节点上的 agent(kubelet)就开始干活了。
kubelet #
每个 K8s node 上都会运行一个名为 kubelet 的 agent,它负责 pod 生命周期管理,会负责将 pod 的逻辑抽象转换为具体的容器,包括执行挂载目录、创建容器日志、垃圾回收等动作
Pod Sync 状态同步 #
kubelet 会 List&Watch pod 的状态变化,通过 List&Watch 接口,kubelet 获取到当前 Node 的 pod 列表(根据 spec.nodeName 过滤),随后与自己的 Pod 缓存列表进行对比,如果有 Pod 的创建、删除、更新,就会开始状态同步。
The workflow is:
- If the pod is being created, record pod worker start latency
- Call generateAPIPodStatus to prepare an v1.PodStatus for the pod
- If the pod is being seen as running for the first time, record pod start latency
- Update the status of the pod in the status manager
- Kill the pod if it should not be running
- Create a mirror pod if the pod is a static pod, and does not already have a mirror pod
- Create the data directories for the pod if they do not exist
- Wait for volumes to attach/mount
- Fetch the pull secrets for the pod
- Call the container runtime’s SyncPod callback
- Update the traffic shaping for the pod’s ingress and egress limits
-
如果是 pod 创建事件,会记录一些 pod latency 相关的 metrics;
-
然后调用
generateAPIPodStatus()生成一个v1.PodStatus对象,代表 pod 当**前阶段 (Phase)**的状态。Pod 的 Phase 是对其生命周期中不同阶段的高层抽象,包括 Pending、Running、Succeeded、Failed、Unknown 等状态
首先,顺序执行一系列
PodSyncHandlers。每个 handler 判断这个 pod 是否还应该留在这个 node 上。 如果其中任何一个判断结果是否,那 pod 的 phase 将变为 PodFailed 并最终会被从这个 node 驱逐。一个例子是 pod 的
activeDeadlineSeconds(Jobs 中会用到)超时之后,就会被驱逐。接下来决定 Pod Phase 的将是其 init 和 real containers。由于此时容器还未启动,因此 将处于 waiting 状态。 有 waiting 状态 container 的 pod,将处于 Pending Phase。
-
PodStatus 生成之后,将发送给 Pod status manager,后者的任务是异步地通过 apiserver 更新 etcd 记录。
-
接下来会运行一系列 admission handlers,确保 pod 有正确的安全权限(security permissions)。
其中包括 enforcing AppArmor profiles and NO_NEW_PRIVS。 在这个阶段被 deny 的 Pods 将无限期处于 Pending 状态。
-
如果指定了
cgroups-per-qos,kubelet 将为这个 pod 创建 cgroups。可以实现更好的 QoS。 -
为容器创建一些目录。包括
- pod 目录 (一般是 /var/run/kubelet/pods/
) - volume 目录 (
/volumes) - plugin 目录 (
/plugins).
- pod 目录 (一般是 /var/run/kubelet/pods/
-
volume manager 将等待
Spec.Volumes中定义的 volumes attach 完成。这取决于 volume 类型,pod 可能会等待很长时间(例如 cloud 或 NFS volumes)。 -
从 apiserver 获取
Spec.ImagePullSecrets中指定的 secrets,注入容器。 -
容器运行时(runtime)创建容器(后面详细描述)。
CRI 及创建 pause 容器 #
至此,容器创建的准备工作已经做完了,接下来会根据 container runtime 来创建容器。
kubelet 使用 **CRI (Container Runtime Interface) **与具体的容器运行时交互。 简单来说,CRI 提供了 kubelet 和具体 runtime implementation 之间的抽象接口, 用 protocol buffers 和 gRPC 通信。
Sync Pod #
// pkg/kubelet/kuberuntime/kuberuntime_manager.go
// SyncPod syncs the running pod into the desired pod by executing following steps:
// 1. Compute sandbox and container changes.
// 2. Kill pod sandbox if necessary.
// 3. Kill any containers that should not be running.
// 4. Create sandbox if necessary.
// 5. Create ephemeral containers.
// 6. Create init containers.
// 7. Create normal containers.
//
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus,
pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
if podContainerChanges.CreateSandbox {
ref := ref.GetReference(legacyscheme.Scheme, pod)
if podContainerChanges.SandboxID != "" {
m.recorder.Eventf("Pod sandbox changed, it will be killed and re-created.")
} else {
InfoS("SyncPod received new pod, will create a sandbox for it")
}
}
// Step 2: Kill the pod if the sandbox has changed.
if podContainerChanges.KillPod {
if podContainerChanges.CreateSandbox {
InfoS("Stopping PodSandbox for pod, will start new one")
} else {
InfoS("Stopping PodSandbox for pod, because all other containers are dead")
}
killResult := m.killPodWithSyncResult(pod, ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}
} else {
// Step 3: kill any running containers in this pod which are not to keep.
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
killContainerResult := NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
m.killContainer(pod, containerID, containerInfo)
}
}
// Keep terminated init containers fairly aggressively controlled
// This is an optimization because container removals are typically handled by container GC.
m.pruneInitContainersBeforeStart(pod, podStatus)
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod))
result.AddSyncResult(createSandboxResult)
podSandboxID, msg = m.createPodSandbox(pod, podContainerChanges.Attempt)
podSandboxStatus := m.runtimeService.PodSandboxStatus(podSandboxID)
}
// the start containers routines depend on pod ip(as in primary pod ip)
// instead of trying to figure out if we have 0 < len(podIPs) everytime, we short circuit it here
podIP := ""
if len(podIPs) != 0 {
podIP = podIPs[0]
}
// Get podSandboxConfig for containers to start.
configPodSandboxResult := kubecontainer.NewSyncResult(ConfigPodSandbox, podSandboxID)
result.AddSyncResult(configPodSandboxResult)
podSandboxConfig := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt)
// Helper containing boilerplate common to starting all types of containers.
// typeName is a label used to describe this type of container in log messages,
// currently: "container", "init container" or "ephemeral container"
start := func(typeName string, spec *startSpec) error {
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, spec.container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg := m.doBackOff(pod, spec.container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
return err
}
m.startContainer(podSandboxID, podSandboxConfig, spec, pod, podStatus, pullSecrets, podIP, podIPs)
return nil
}
// Step 5: start ephemeral containers
// These are started "prior" to init containers to allow running ephemeral containers even when there
// are errors starting an init container. In practice init containers will start first since ephemeral
// containers cannot be specified on pod creation.
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
// Step 6: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
start("init container", containerStartSpec(container))
}
// Step 7: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
start("container", containerStartSpec(&pod.Spec.Containers[idx]))
}
}
create sandbox #
kubelet 发起 RunPodSandbox RPC 调用。
如果我们的容器 runtime 是 containerd,那接下来就会调用到 docker/containerd 相关代码,细节可以参考以下文章:
在 runtime 中,创建一个 sandbox 会转换成创建一个 pause container 的操作。 Pause container 作为一个 pod 内其他所有容器的父角色,hold 了很多 pod-level 的资源, 具体说就是 Linux namespace,例如 IPC NS、Net NS、IPD NS。
pause container 提供了一种持有这些 ns、让所有子容器共享它们 的方式。 例如,共享 netns 的好处之一是,pod 内不同容器之间可以通过 localhost 方式访问彼此。 pause 容器的第二个用处是回收(reaping)dead processes。 更多信息,可参考 这篇博客。
CNI #
pod 已经有了一个占坑用的 pause 容器,它占住了 pod 需要用到的所有 namespace。 接下来需要做的就是:调用底层的具体网络方案(bridge/flannel/calico/cilium 等等) 提供的 CNI 插件,创建并打通容器的网络。
CNI 是 Container Network Interface 的缩写,工作机制与 Container Runtime Interface 类似。简单来说,CNI 是一个抽象接口,不同的网络提供商只要实现了 CNI 中的几个方法,就能接入 K8s,为容器创建网络。kubelet 与CNI 插件之间通过 JSON 数据交互(配置文件放在 /etc/cni/net.d),通过 stdin 将配置数据传递给 CNI binary (located in /opt/cni/bin)。
随后,CNI plugin manager 调用到具体的 CNI 插件(可执行文件), 执行 shell 命令为容器创建网络:
接下来就是 CNI 插件为容器创建网络,也就是可执行文件 /opt/cni/bin/xxx 的实现。
CNI 相关的代码维护在一个单独的项目 github.com/containernetworking/cni。每个 CNI 插件只需要实现其中的几个方法,然后编译成独立的可执行文件,放在 /etc/cni/bin 下面即可。
创建 init 容器及业务容器 #
至此,网络部分都配置好了。接下来就开始启动真正的业务容器。
Sandbox 容器初始化完成后,kubelet 就开始创建其他容器。 首先会启动 PodSpec 中指定的所有 init 容器, 代码 然后才启动主容器(main containers)
过程:
-
拉镜像。 如果是私有镜像仓库,就会从 PodSpec 中寻找访问仓库用的 secrets。
-
通过 CRI 创建 container。
从 parent PodSpec 的 ContainerConfig struct 中解析参数(command, image, labels, mounts, devices, env variables 等等), 然后通过 protobuf 发送给 CRI plugin。例如对于 docker,收到请求后会反序列化,从中提取自己需要的参数,然后发送给 Daemon API。 过程中它会给容器添加几个 metadata labels (例如 container type, log path, sandbox ID)。
-
然后通过
runtimeService.startContainer()启动容器; -
如果注册了 post-start hooks,接下来就执行这些 hooks。post Hook 类型:
- Exec:在容器内执行具体的 shell 命令。
- HTTP:对容器内的服务(endpoint)发起 HTTP 请求。 如果 PostStart hook 运行时间过长,或者 hang 住或失败了,容器就无法进入 running 状态。
至此,应该已经有 3 个 pod 在运行了,取决于系统资源和调度策略,它们可能在一台 node 上,也可能分散在多台。