kube-scheduler 是 kubernetes 核心组件中的一个,负责将新创建的 pod 调度到集群中合适的节点上运行。
Kubernetes 调度本质上是一个背包问题,涉及到多维多重背包、组合背包、依赖背包等。在一些学术界的观点中,云资源调度被认为与非确定性多项式 (Nondeterministic Polynomial, NP) 优化问题具有同等复杂度,是一个 NP-hard 问题。
Scheduler 在整个系统中承担了"承上启下"的重要功能。它负责接受 Controller Manager 创建的新 Pod,为其安排合适的 Node;另一方面又在安置工作完成后,目标 Node 上的 kubelet 服务进程接管后续工作。Pod 是 Kubernetes 中最小的调度单元。
入口 #
kube-scheduler 的核心调度逻辑通过 sched.Run(ctx) 启动:
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
// 启动调度队列,调度队列 watch 待调度的 pod
sched.SchedulingQueue.Run(logger)
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
// 轮询执行 sched.scheduleOne,其会消费调度队列中待调度的 pod,执行完成 pod 的调度
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
// 清理释放资源
sched.SchedulingQueue.Close()
}
调度模型 #
经过入口之后,就开始了 kube-scheduler 的调度过程。scheduler 调度模型如图:
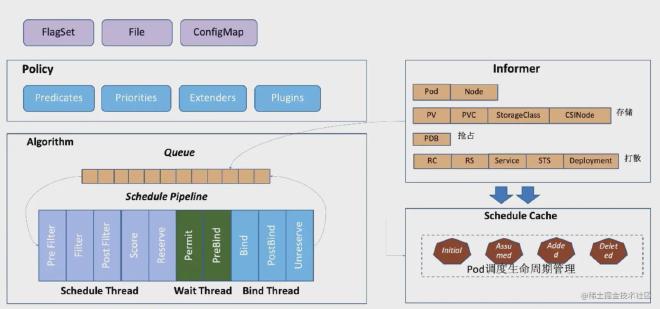
主要分为三个部分:
- Policy:Scheduler 的调度策略启动配置目前支持三种方式,配置文件/命令行参数/ConfigMap。调度策略可以配置指定调度主流程中要用哪些过滤器(Predicates)、打分器(Priorities) 、外部扩展的调度器(Extenders),以及 SchedulerFramwork 的自定义扩展点(Plugins)
- Informer:Scheduler 在启动的时候通过 K8s 的 informer 机制通过 List&Watch 从 kube-apiserver 获取调度需要的数据。例如: Pods、Nodes、Persistant Volume (PV), Persistant Volume Claim(PVC)等等,并将这些数据做一定的预处理,作为调度器的的 Cache。
- 调度流水线:通过 Informer 将需要调度的 Pod 插入 Queue 中,Pipeline 会循环从 Queue Pop 等待调度的 Pod 放入 Pipeline 执行。调度流水线(Schedule Pipeline)主要有三个阶段:Scheduler Thread,WaitThread,Bind Thread.
- Scheduler Thread 阶段:Schduler Thread 会经历 Pre Filter -> Filter -> Post Filter-> Score -> Reserve,可以简单理解为 Filter -> Score -> Reserve。Filter 阶段用于选择符合 Pod Spec 描述的 Nodes;Score 阶段用于从 Filter 过后的 Nodes 进行打分和排序;Reserve 阶段将 Pod 预留资源到排序后的最优 Node 的 NodeCache 中,表示这个 Pod 已经分配到这个 Node 上, 让下一个等待调度的 Pod 对这个 Node 进行 Filter 和 Score 的时候能看到刚才分配的 Pod
- Wait Thread 阶段:这个阶段可以用来等待 Pod 关联的资源的 Ready 等待,例如等待 PVC 的 PV 创建成功,或者 Gang 调度中等待关联的 Pod 调度成功等;
- Bind Thread 阶段:用于将 pod 和 node 的关系持久化到 apiserver。
整个调度流水线只有在 Scheduler Thread 阶段是串行的一个 Pod 一个 Pod 的进行调度,在 Wait 和 Bind 阶段 Pod 都是异步并行执行。
scheduling framework #
kubernetes 在 1.15 版本之后,引入了这种比较灵活的调度框架。调度框架是面向 Kubernetes 调度器的一种插件架构, 它由一组直接编译到调度程序中的“插件” API 组成。这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。(调度框架的设计提案)
调度框架定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。每个插件支持不同的调度扩展点,一个插件可以在多个扩展点处注册,以执行更复杂或有状态的任务。
每次调度一个 Pod 的尝试都分为两个阶段,即调度周期和绑定周期。调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。二者一起被称为“调度上下文”。调度周期是串行运行的,而绑定周期可能是同时运行的。如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或绑定周期,Pod 将返回队列并重试。
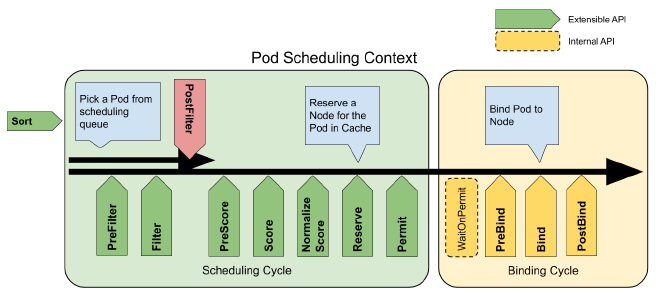
调度扩展点:
kube-scheduler 调度逻辑运行依赖 Scheduler 的实现,其中包含了调度逻辑运行所依赖的接口和方法。其创建如下:
// cmd/kube-scheduler/app/server.go
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
// 设置 kubeSchedulerConfiguration 的默认配置,后续 opt.CommontConfig 会根据具体文件重新配置
if cfg, err := latest.Default(); err != nil {
return nil, nil, err
} else {
opts.ComponentConfig = cfg
}
if errs := opts.Validate(); len(errs) > 0 {
return nil, nil, utilerrors.NewAggregate(errs)
}
// 检查 *options.Options 合法性
c, err := opts.Config(ctx)
if err != nil {
return nil, nil, err
}
// Get the completed config 补全需要的字段
cc := c.Complete()
// 初始化 runtime.Registry 实例,保存所有的 Out-Of-tree 插件
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
completedProfiles := make([]kubeschedulerconfig.KubeSchedulerProfile, 0)
// Create the scheduler. 穿件调度器实例,用来运行所有的 kube scheduler 调度逻辑
sched, err := scheduler.New(ctx,
cc.Client,
cc.InformerFactory,
cc.DynInformerFactory,
recorderFactory,
// option 模式来配置
scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
scheduler.WithKubeConfig(cc.KubeConfig),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...), // 自定义的调度策略
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
if err != nil {
return nil, nil, err
}
if err := options.LogOrWriteConfig(klog.FromContext(ctx), opts.WriteConfigTo, &cc.ComponentConfig, completedProfiles); err != nil {
return nil, nil, err
}
return &cc, sched, nil
}
// pkg/scheduler/scheduler.go
type schedulerOptions struct {
clock clock.WithTicker
componentConfigVersion string
kubeConfig *restclient.Config
// Overridden by profile level percentageOfNodesToScore if set in v1.
// node 得分的百分比,如果在 v1 中设置了 profile 级别的 percentageOfNodesToScore,就会被覆盖
percentageOfNodesToScore int32
podInitialBackoffSeconds int64 // pod 初始退避时间
podMaxBackoffSeconds int64 // pod 最大退避时间
podMaxInUnschedulablePodsDuration time.Duration // 最大不可调度的 pod 时间
// Contains out-of-tree plugins to be merged with the in-tree registry.
// 包含外部插件,用于和内部插件合并·
frameworkOutOfTreeRegistry frameworkruntime.Registry
// 调度器配置文件
profiles []schedulerapi.KubeSchedulerProfile
// 调度器扩展
extenders []schedulerapi.Extender
// 用于捕获调度框架的函数
frameworkCapturer FrameworkCapturer
// 调度器的并行度
parallelism int32
// 是否应用默认配置文件
applyDefaultProfile bool
}
调度插件 #
kube-scheduler 通过一系列的调度插件最终完成 pod 的调度。在启动 kube-scheduler 时,首先加载调度插件。对于调度插件,有 in-tree 和 out-of-tree 两种。
- In-Tree:内建插件,作为 Kubernetes 核心组件的一部分直接编译和交付的, 与 Kubernetes 的源代码一起维护,并与 Kubernetes 版本保持同步。这些插件以静态库形式打包到 kubescheduler 二进制文件中,因此在使用时不需要单独安装和配置。一些常见的 in-tree 插件包括默认的调度算法、Packed Scheduling 等。
- Out-of-tree:外部插件,作为独立项目开发和维护的,与 Kubernetes 核心代码分开,并且可以单独部署和更新。本质上,out-of-tree 插件是基于 Kubernetes 的调度器扩展点进行开发,这些插件以独立的二进制文件形式存在,并通过自定义的方式与 kube-scheduler 进行集成,需要单独安装和配置,并在 kube-scheduler 的配置中指定。
kube-scheduler 首先加载 out-of-tree 插件,在 main 文件中需要调用 app.NewSchedulerCommand() 来创建一个 scheduler application,示例。在调用 app.NewSchedulercommand 时,我们通过 app.WithPlugin option 模式,传入了我们期望加载到 kube-scheduler 中的 out-of-tree 插件。一般情况下:
- 开发 out-of-tree 插件时,为了避免改动 kubernetes 源码仓库中的 kube-scheduler 源码,我们一般会另起一个项目,例如:scheduler-plugins。在新项目中我们调用 Kubernetes 源码仓库中的
app包,来创建-个跟 kube-scheduler 完全一致的调度组件; - 创建应用时直接调用
k8s.io/kubernetes/cmd/kube-scheduler/app.NewSchedulerCommand(),所以创建的调度器可以和 kube-scheduler 保持兼容。
一个具体的外部实现可以参考 PodState 插件
对于 In-Tree 插件具体实现在 pkg/scheduler/framework/plugins/ 目录下。如 NodeName 插件的实现。
调度策略 #
调度策略用来执行具体的调度逻辑。kube-scheduler 在调度时,会选定一个调度策略,并使用该调度策略进行调度。同时,kube-scheduler 也支持自定义调度策略。 kube-scheduler 支持以下3种调度策略:
-
Scheduler Extender:社区最初提供的方案是通过 Extender 的形式来扩展 scheduler。Extender 是外部服务,支持 Filter、Preempt、Prioritize 和 Bind 的扩展,schneduler 运行到相应阶段时,通过调用 Extender 注册的 webhook 来运行扩展的逻辑,影响调度流程中各阶段的决策结果。
-
Multiple schedulers:在 Kubernetes 集群中其实类似于一个特殊的 Controller,通过监听 Pod和 Node 的信息,给 Pod 挑选最佳的节点、更新 Pod 的 spec,NodeName 的信息来将调度结果同步到节点所以对于部分有特殊的调度需求的用户,有些开发者通过自研 Custom Scheduler 来完成以上的流程,然后通过和 default-scheduler 同时部署的方式,来支持自己特殊的调度需求。在
Pod.Spec.SchedulerName字段中,可以设置该 Pod 的调度策略,默认为:default; -
Scheduling Framework:在原有的调度流程中,定义了丰富扩展点接口,开发者可以通过实现扩展点所定义的接口来实现插件,将插件注册到扩展点。Scheduling Framework 在执行调度流程时,运行到相应的扩展点时,会调用用户注册的插件,影响调度决策的结果。通过这种方式来将用户的调度逻辑集成到 Scheduling Framework 中。
调度队列管理 #
PriorityQueue 优先队列,包含三个子队列:activeQ、backoffQ、unschedulableQ。
-
activeQ:Scheduler 启动的时候所有等待被调度的 Pod 都会进入 activieQ,activeQ 按照 Pod 的 priority 进行排序,Scheduler Pipepline 从 activeQ 获取一个 Pod 并执行调度流程(Pipepline),当调度失败之后会直接根据情况选择进入 unschedulableQ 或者 backoffQ ,如果在当前 Pod 调度期间 Node Cache、Pod Cache 等 Scheduler Cache 有变化就进入 backoffQ,否则进入 unschedulableQ .
-
backoffQ:退避队列。持有从 unschedulablePods 中移走的 Pod,并将在其 backoff periods 退避期结束时移动到 activeQ 队列。Pod 在退避队列中等待并定期尝试进行重新调度。重新调度的频率会按照一个指数级的算法定时增加,从而充分探索可用的资源,直到找到可以分配给该Pod 的节点。
-
unschedulableQ:不可调度 Pod 的列表。持有已尝试进行调度且当前确定为不可调度的 Pod。
unschedulableQ 会定期较长时间(例如 60 秒)刷入 activeQ 或者 backoffQ,或者在 SchedulerCache 发生变化的时候触发关联的 Pod 刷入 activeQ 或者 backoffQ; backoffQ 会以 backoff 机制相比 unschedulableQ 比较快地让待调度的 Pod 进入 activeQ 进行重新调度。
调度 pod #
当获取到一个待调度的 Pod 后,就会调用 sched.schedulingcycle 进入到调度循环中。schedulingCycle 函数执行 Pod 调度逻辑。 schedulingCycle 函数中,会按顺序依次执行以下调度扩展点: Prefilter、Filter、PostFilter、PreScore、Score、Reserve、Permit
调度引擎中,真正影响调度效果的是调度插件。行业中,针对不同的调度场景(例如:在线场景、离线场景、AI训练场景等),实现了不同的 kube-scheduler 调度插件,kube-scheduler 源码仓库中,也内嵌了一些常用的调度插件。
部分调度插件实现:
- kube-scheduler In-Tree 调度插件实现:位于 pkg/scheduler/framework/plugins 下
- 简单的实现:node_unschedulable
- 稍复杂的实现:nodeResourcesFit
- 社区插件:
- coscheduling (协同调度):scheduling framework 机制下的第一个插件,可用于 AI 场景下的,批调度插件。能够确保期望的 Pod 数,被同时调度成功。
调度拓展 #
kubernetes 原生的 default-scheduler 支持较好的在线业务负载,除此之外,Scheduler 向上有一些场景还需要为离线作业(批式、流式、AI 训练等)提供扩展调度支持,比如 Gang/Binpack/Capacity 等语义。
Gang scheduling #
在并发系统中将多个相关联的进程调度到不同处理器上同时运行的策略,被称为 Coscheduling,在这个场景中,需要保证所有相关联的进程能够同时启动,防止部分进程的异常,导致整个关联进程组的阻塞。这种导致阻塞的部分异常进程,称为碎片 (fragement)。具体实现中,根据是否允许碎片存在,可以细分为 Explicit Coscheduling, Local Coscheduling, Implicit Coscheduling. 其中 Explicit Coscheduling 就是的 Gang Scheduling。
Gang Scheduling 要求完全不允许有碎片存在,如果集群能够满足一个作业的所有子任务的需求,才为任务整体分配资源,否则不为其分配任何资源。即 All or Nothing 的模式。
由于 kubernetes 原生的调度器是以 pod 为单位进行依次调度,不会在调度过程中考虑 pod 之间的关系,而且集群资源无法满足 job 请求的所有资源时可能出现部分 pod 无法启动,已经创建的 pod 无法运行,造成资源的浪费。因此,需要扩展 Kubernetes 调度器支持 Gang Scheduling 策略,避免资源死锁
BinPack #
Binpack(装箱调度) 是一种资源调度策略,旨在通过最大化单个节点的资源利用率来减少资源碎片,从而提升集群整体的资源使用效率。
kubernetes 的默认资源调度策略为 LeastRequestedPriority,即消耗资源最少的节点得分最高,优先被调度。这种 Spread 策略使集群的资源使用在所有节点之间分配得相对均匀,但是往往也会在单个节点上产生较多资源碎片,使得整体资源利用率下降。而对于 Kubernetes 提供的 MostRequested 策略,仅支持 CPU + Memory 的形式进行 Binpack, 无法支持 Extended Resource, 如 GPU。
因此需要节点级别的 Binpack,可以通过原生的调度策略 RequestedToCapacityRatio 配置 CPU/Memory/GPU 等资源的权重,作用于优选阶段给节点打分。在打分阶段计算资源的分配率,根据分配率进行排序,优先打满一个节点后再向后调度
通过 Binpack 策略减少资源碎片,从而可以避免小作业饿死大作业,以及提升 GPU 等资源的利用率
Capacity #
在大数据场景下,多租户使用同一个集群时,通常需要进行 Quota 的限制,保障每个租户的资源需求。为了提升集群的资源利用率,当某个租户有空闲资源时,可以出让给其他租户使用。
Kubernetes 原生的多租户 Quota 是通过 Namespace + ResourceQuota 方式进行管理的,对于 ResourceQuota 这种方式而言,通过 Admission Control 机制实现,和调度是分离的,可能在 kube-apiserver 中准入成功,更新了 ResourceQuota 中已使用的资源,但后续 Scheduler 调度失败,不能及时释放导致该部分资源不能被其他 Pod 使用。而且 ResourceQuota 为硬隔离,无法支持租户间资源的弹性出让
这时可以将 Quota 的准入从 kube-apiserver 的 Admission Control 阶段,迁移到 Scheduler 的调度过程中。
Quota 引入 min/max 机制,通过借用、抢占等方式,实现弹性管理。Min: 可以使用的保障资源 (Guaranteed Resource), 当资源紧张时可以保证分配的资源量;Max: 可以使用的资源上限 (包含弹性资源)
GPU 共享调度 #
原生 Kubernetes 仅支持以 GPU 整卡粒度为单位调度,任务容器会独占 GPU 卡。如果任务模型比较小(计算量、显存用量),就会造成 GPU 卡资源空闲浪费。
业界解决方案有阿里云 cGPU 与腾讯云 qGPU,通过容器 GPU 虚拟化解决,通过软件方式来实现 GPU 卡在算力和显存方面更小粒度的切分和隔离,最终达到一张卡能够被多个应用来使用,从而提升 GPU 卡的整体使用率。
除了容器对 GPU 的隔离能力,还需要在调度上支持 GPU 共享,即:按模型的 GPU 算力和显存需求量,为任务选择最优的节点,将一块 GPU 卡分配给多个任务容器共享使用,用更多任务最大限度地占满 GPU 资源。
在调度策略上,一般需要支持下列不同的分配策略:
-
单容器单 GPU 卡共享,常用于支持模型推理场景;
-
单容器多 GPU 卡共享,常用于开发环境中调试分布式模型训练;
-
GPU 卡级别的 Binpack/Spread 策略,可以平衡 GPU 卡的分配密度和可用性。
-
https://juejin.cn/post/7222210580320124987?searchId=202503251551273605E8CD67D3BEA8D421