可观测性 #
指标 #
Metric 是在运行时捕获的服务测量值,是对一段时间内基础设施或应用程序的数值数据的汇总。例如:系统错误率、CPU使用率和特定服务的请求率。通过 metrics 可以获取系统的运行状态,是否存在异常,但是不能获取现场
日志 #
日志是由服务或其他组件发出的带时间戳的消息,它是离散非结构化的,能一定程度上还原现场信息。但仅靠日志来追踪代码执行还不够,因为日志通常缺乏上下文信息,比如它们是从哪里被调用的。而且日志如果输出不合理,可能占用大量的存储、IO、带宽等资源
链路(追踪) #
记录了请求(无论是来自应用程序还是终端用户)在多服务架构(如微服务和无服务器应用)中传播的路径。一个**链路(Tracing)**由一个或多个 span 组成。第一个 span 被称为根 span,它代表了一个请求从开始到结束的全过程。根 span 下的子 span 则提供了请求过程中更详细的上下文信息(或者说,构成了请求的各个步骤)。
可观测性后端会将链路可视化为瀑布图:

-
寻找最长的 span,这个 span 会影响到链路的持续时间,可以检查优化该 span 部分的逻辑。如果 span 的时长不会影响到整体链路的延迟,可以根据情况来忽略。
-
阶梯状的 span 表示顺序执行的任务,视特定情况来分析,是否需要顺序执行。可以进行并发的设计来优化。
-
如果子 span 没有覆盖父 span,叶子节点之间存在间隙,通常表示缺少埋点,有可能在等待一个服务请求结束。
profiler #
profiler 是一种单进程性能分析工具,Golang 内置的采样可以导出 pprof 文件,分析程序的 CPU 占用情况、内存占用情况、goroutine 占用情况、阻塞情况等。
可以说,Golang 火焰图中的事件越宽(占父事件的百分比越高),颜色越深(全局的百分比越高),则事件执行事件越长,需要关注。
性能优化 #
链路优化(服务间调用优化) #
负载均衡 #
DNS 解析
通过配置 dns 解析服务器把请求打到不同的服务,避免一台机器承载太多请求。也有些公司使用 http-dns。http-dns 使用 HTTP 协议与 DNS 服务器交互,代替传统的基于 UDP 的 DNS 协议,域名解析请求直接发送到 http-dns 服务端,从而绕过运营商的 Local DNS,防止域名劫持、实现精准调度。
七层负载均衡
七层是指网络模型的第七层,即应用层,根据应用层的信息去对请求做负载均衡。如 Nginx、Treafik、Envoy 等
四层负载均衡
四层是指工作在网络模型第四层,即传输层,主要通过 tcp 四元组来直接转发流量。不需要额外维护 tcp 链接,拥有较好的性能。如软件级别的 LVS 通过修改 ip 地址的方式来实现转发,工作在 linux 内核层。还有硬件级别的 F5,不过一半价格昂贵
负载均衡算法
常见的有 random 或者 round robin(轮询),可以将负载请求转发到不同的服务实例上,还可以对不同的服务实例进行加权
最小活跃请求算法,将请求发往排队数量较少的实例上,减少排队等待时间
基于历史指标进行预测的负载均衡算法
哈希
一致性哈希
计算逻辑本地化 #
即将计算逻辑放在本地来执行,减少网络链路上的开销,同时也可以防止中心化服务劣化时对整体性能上造成损失。常见的有 sdk、动态插件、sidecar 几种方式,其中动态插件和 sidecar 可以实现业务的无感更新。
-
sdk 嵌入到业务代码中,减少了中间通信的成本,但是对代码侵入性很大
-
动态插件,同样嵌入到代码中,没有中间通信,需要提前定义拓展点以及缺少插件时的默认逻辑
-
sidecar 与业务代码完全解耦,独立于业务代码进行更新和透明流量拦截,但是需要进行进程间通信以及序列话和反序列化,多了一些成本
服务间拓扑优化 #
业务流程、架构优化 #
同步/异步优化 #
将没有依赖关系的多个子任务并行执行,当需要前置任务时再等待,如图所示:
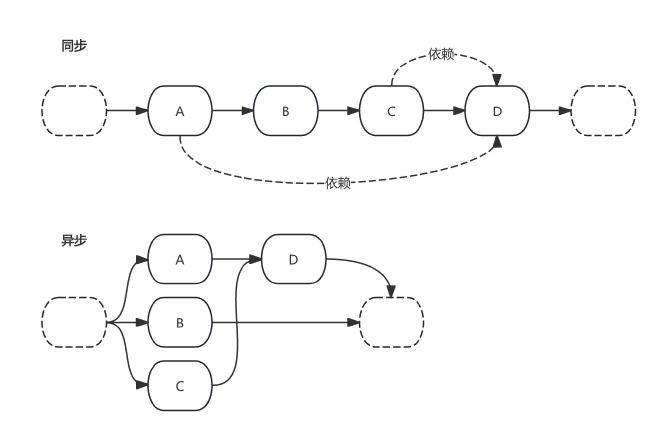
需要注意的是,如果 CPU 资源不足以支撑并行,实际的耗时取决于调度器的实现。一般情况下,主流调度器的实现(FIFO、O(1)、CFS 等调度器)都会保证任务在一个调度周期内被调度,不会出现任务被饿死的情况,而调度器的开销一般在业务中都可以忽略不计。如果并行带来了协程开销的问题,可以考虑引入协程池来优化。
对于有层级关系的任务执行结构,可以考虑转换成 DAG(Directed Acyclic Graph,有向无环图)结构,如下图:
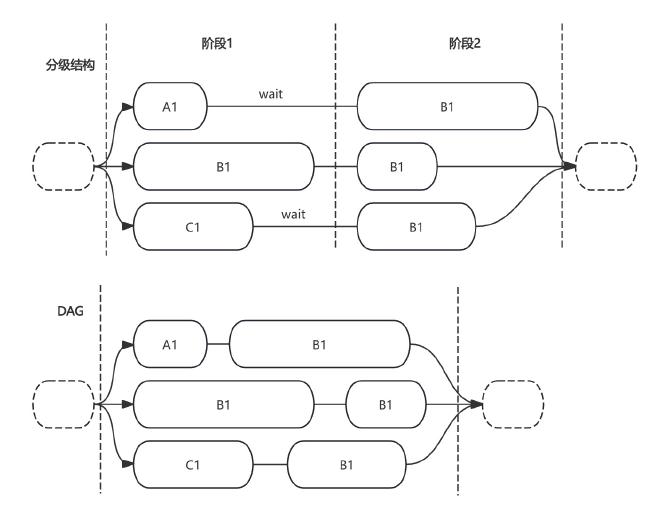
在一些架构中存在一些分级结构,在并行任务或请求中会等待所有任务完成,等待完成后再执行下一级任务。但是任务执行时间是不同的,这时每一级的执行时间变成了最长执行任务的时间,导致了时间的浪费。如果按照 DAG 结构重新进行建模,在具有依赖关系的节点,前置任务执行完成后马上执行后续任务,可以避免不必要的等待。
弱依赖超时降级 #
数据流中弱依赖一般为核心能力的补充,不会对用户体验造成影响。可以对弱依赖设置比较严格的超时时间,实现动态降级能力
对访问频率高的数据进行前置 #
在 CPU(L1/L2/L3 Cache)、数据库、操作系统中都比较场景,是一种比较通用的思维方式。对于静态内容通过 cdn 减少用户和数据存储之间的延时,对于更新频率不高或者实时性需求不高的数据可以缓存到带有淘汰策略(选择适合的淘汰策略,如 LRU 等)的本地缓存或分布式 kv 存储中。
对于重复的操作,可以使用缓存来避免冗余的计算。
同样,对于一些场景也可以延迟计算或按需计算,即不需要对所有结果进行计算,只对部分结果进行求值,或者只在需要的时候进行求值。
语言运行时优化 #
对于不同的语言,对应有不同的运行时优化方法,如垃圾回收优化、调整对象分配等,针对具体语言和具体场景进行优化。以下针对 Golang 提供集中优化思路
栈分裂 #
栈分裂 是一种管理协程(Goroutines)的栈内存的机制,以提高 Go 的并发能力。栈分裂使得每个协程可以用较小的初始栈开始,并根据需要动态扩展。在 Go 的早期版本中,调整了几次最小栈内存,在 go/1.14 之后,最小栈内存降低至 2KB
对于新的 Goroutine 默认分配 2KB,当栈长度过大时就会触发栈的拷贝(go1.16 linux 默认 stackguard 为 928,实际当栈长度达到 1120byte 时就会触发栈拷贝)。此时 copystack 函数遍历旧栈上的所有栈帧信息和可能的指针位置,使指针指向新栈。一般需要:
- 计算扩容后栈的大小(一般为2倍,但是如果当前函数较大,也会增加到4倍甚至8倍)
- 申请新的内存。拷贝当前栈的内容至新的内存
- 遍历栈帧,逐帧修改指向旧栈的指针
- 销毁并回收旧栈
可见栈分裂会复制原栈内容并遍历,对性能有比较重的影响。
runtime.morestack.abi0 => runtime.newstack => runtime.copystack 占比较大时,可能栈分裂对性能出现了影响
有几种方式来应对栈分裂
- 增加栈空间
- 动态调整栈内存大小:Go 运行时支持动态调整栈内存大小,可以通过
runtime包来动态调整。 - 使用大页面:Linux 内核支持大页面(Large Page) 来存储栈帧,减少页错误。
- 动态调整栈内存大小:Go 运行时支持动态调整栈内存大小,可以通过
- 减少栈内存的使用
- 使用内联函数:将小的函数内联到调用点,减少栈的开销,减少栈帧的大小
- 递归优化:设置递归深度的上限,或者使用尾递归优化
- 减少栈帧的大小:减少函数内局部变量的数据和大小;局部变量静态分配代替动态分配;大的局部变量放在堆上而不是栈上
- 数据机构、算法优化
- 复用协程栈
- 复用之前已经扩容过的协程栈来避免频繁的栈扩容。
缓存优化 #
优化深拷贝带来的开销
在需要对对象进行深拷贝时,我们有时会使用 Marshal&Unmarshal 或者 reflect.DeepCopy,这些都是基于 golang 的反射来实现的,运行时过程中通过反射来获取源对象和目标对象的结构信息,包括字段名称、类型、tag 等,这其中涉及到了各种元数据的查询、类型判断、类型转换、检查,对于只是类型转换的场景来说这些都是不必要的处理,会造成性能损失,可以进行优化。可以通过 goverter,根据对象结构生成静态的代码,将类型判断提前到编译期。另外 kubebuilder、kitex 等代码生成的 DeepCopy 方法也可以参考
内存对齐 #
减少指针使用
对于返回值来说,指针结构或者占用比较大的结构,都会逃逸到堆上
json 优化
字符串格式化
数字格式化使用 strconv,字符串拼接使用 strings.Builder
内存分配、缓存优化 #
数组等数据结构存在容量结构,可以预先分配一个足够的空间,减少后期出现频繁的内存分配
arry := make([]user, 1000)
for i := 0; i < 1000; i++ {
arry[i] = user{}
}
对象池 #
在 Golang 中,所有对对象的引用都会逃逸到堆的内存分配上,可以缓存已经分配好的对象,在需要的时候,从缓存中获取并初始化,这样可以减少对象的分配,减少 GC 带来的压力
pool := sync.Pool{}
for i := 0; i < 1000000; i++ {
user := pool.Get().(*user)
// do something
user.reset()
pool.Put(user)
}
性能防劣化 #
技术方案 #
对于新的 Feature 需要判断是否对性能产生影响,考虑优化方案或收益兑换
开发测试 #
功能上线 #
上线观察性能指标,判断是否上线对性能产生影响,考虑是否回滚
灰度发布 #
功能在上线后进行 ab 实验,逐步进行放量,最后推全量。