Kubernetes 是一个用于自动部署、扩展和管理容器化应用程序的开源系统。其基本架构如下图
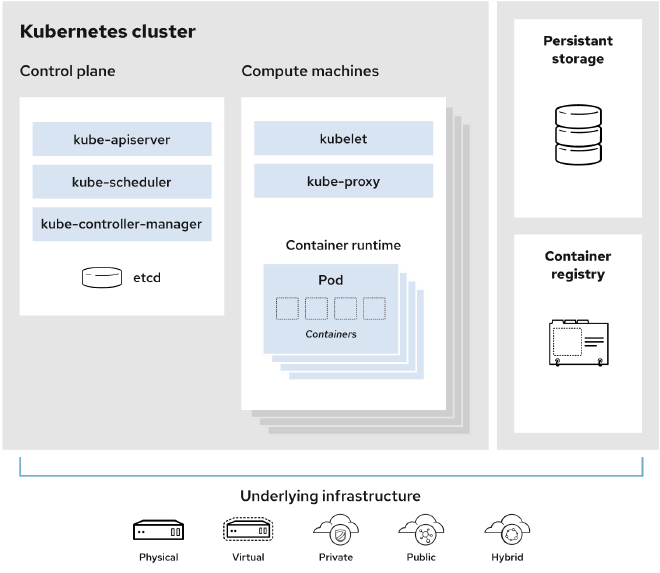
Kubernetes 由一系列核心组件组成,它们在多台主机上协调容器,并提供控制组和命名空间来管理这些容器的资源。在 Kubernetes 中,高可用性是一组旨在提供最低服务水平的配置。例如,当某个节点发生故障时,应用程序仍将具有最低服务水平
Kubernetes 高可用性有两种形式:主动-主动(active-active)和 主动-被动(active-passive)集群。
- 主动-主动集群:双活集群通过在集群中的所有节点上运行多个服务副本来提供高可用性(这种要拆分多集群)
- 主动-被动集群:使用备份节点,在任何给定时间只有一个服务副本在运行
高可用部署方式 #
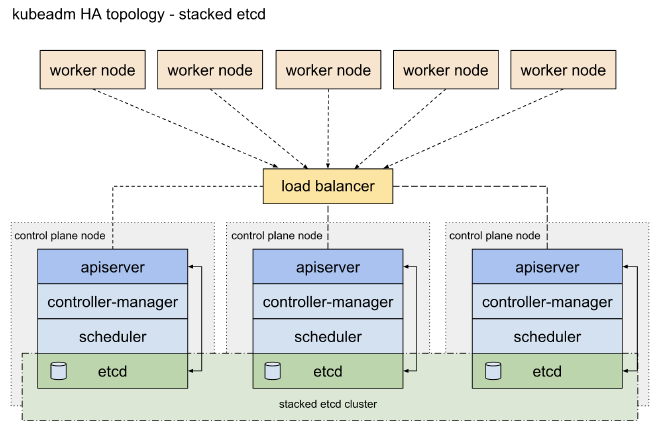
Kubernetes 官方推荐两种 HA 的拓扑,分别是:Stacked etcd topology 和 External etcd topology。两种架构都对 kube-apiserver、kube-scheduler 和 kube-controller-manager 等控制面组件进行了多实例部署,通过负载均衡器暴露给工作节点(worker node),不同的是对 etcd 组件的处理。
对于 Stacked etcd topology,etcd 节点与控制平面节点(Master)共存,每个 Master 节点上运行一个 etcd 实例,每个 Master 节点的 apiserver 仅连接本地 etcd,etcd 集群内部跨节点通信。这种方式相对部署简单,通信速度快,但是由于控制平面与 etcd 强耦合,节点故障会同时影响两者,而且 etcd 集群规模与 Master 节点数量绑定,难以独立扩容。如下图所示
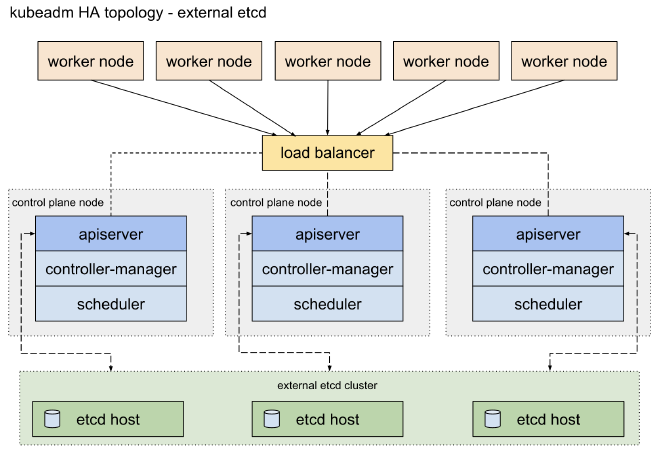
对于 External etcd topology,etcd 集群独立部署在专用节点 上,与控制平面节点物理分离,控制平面与 etcd 解耦,节点故障影响范围更小,但是相对有一定部署、资源成本和网络成本。
ETCD 高可用部署方式 #
-
Etcd 官方文档介绍了如何搭建一个高可用 etcd集群:Clustering Guide
-
k8s 官方文档提供了创建高可用 etcd 集群的方案,不过流程较为复杂:使用 kubeadm 创建一个高可用 etcd 集群
-
一个多地多活的 etcd 集群的方案:Introduction and How-To: etcd clusters for Patroni
自定义 Controller/Scheduler #
自定义控制器和调度器分两种情况接入,一种是直接部署在 master 节点,一种是部署在外部服务,通过 client-go 接入
Node 高可用 #
Kubernetes 本身提供了一整套完善健康检测和容灾方案来保障 Node 和 Pod 的高可用,因为我们更多的是对 Node 的批量扩缩容进行关注,KubeKey 是一个基于 kubeadm 构建的高效安装程序,是 Kubesphere 项目中提供的部署方案,不仅可以提供简易的 K8s 和 Kubesphere 等重要组件的部署,也完成了对 Node 的快速部署和高可用等方案的实现。
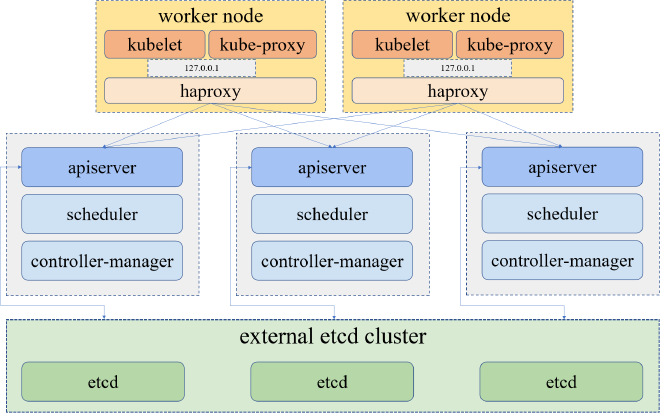
KubeKey 在每个工作节点上部署了一个内置的 HAProxy。所有控制平面节点上的 Kubernetes 组件连接到 kube-apiserver,而工作节点上的组件通过 HAproxy 作为反向代理连接到控制平面节点的 kube-apiserver,通过这种方式提供 HA 模式的支持。
服务监控告警 #
k8s 目前已经完全演变成了以 Prometheus 项目为核心的一套统一的方案。
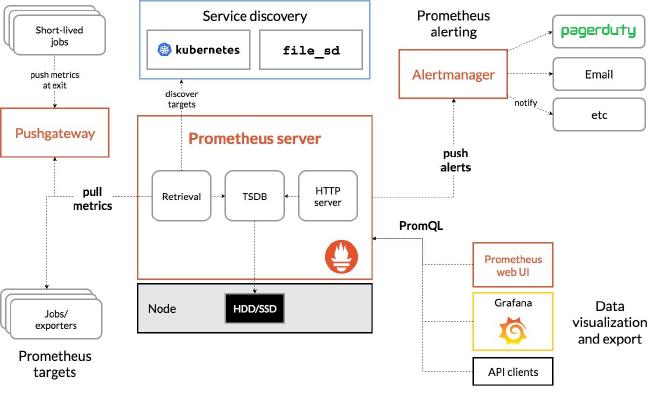
Prometheus 项目工作的核心,是使用 Pull (抓取)的方式去搜集被监控对象的 Metrics 数据(监控指标数据),然后,再把这些数据保存在一个 TSDB (时间序列数据库,比如 OpenTSDB、InfluxDB 等)当中,以便后续可以按照时间进行检索。
有了这套核心监控机制,Prometheus 其余组件用来配合这套机制的运行。比如 Pushgateway,可以允许被监控对象以 Push 的方式向 Prometheus 推送 Metrics 数据。而 Alertmanager,则可以根据 Metrics 信息灵活地设置报警。当然, Prometheus 最受用户欢迎的功能,还是通过 Grafana 对外暴露出的、可以灵活配置的监控数据可视化界面。
基于 Prometheus 不同来源的监控数据主要分为以下三类:
- 宿主机的监控数据:借由 Node Exporter 工具进行抓取并上报给 prometheus
- apiserver、kubelet等组件的监控数据:包括了组件的核心指标,比如队列长队,排队情况,请求延时等数据
- K8s 本身相关的一些核心监控数据:包括了 Pod、Node、容器等 K8s 核心对象的监控数据
这里面提到的 Kubernetes 核心监控数据,其实使用的是 Kubernetes 的一个非常重要的扩展能力,叫作 Metrics Server,有了 Metrics Server 用户就可以通过 API来获取到这些监控数据。Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
容灾恢复 #
Kubernetes 中所有数据都存放在 etcd 中,正常高可用架构已经可以保障单节点失败下服务稳定性,但是极端情况可能会出现多节点故障或者 etcd 全部挂掉的情况,这时候需要容灾恢复方案保障服务能够快速恢复。
-
定期ETCD数据的冷备,以保证服务挂掉时能够降级恢复集群数据
-
空闲服务器的环境准备,在集群数据错误或全部挂掉后,提供备选方案支持
参考 #
- https://kubesphere.io/blogs/k8s-ha-practices/
- https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/select-ecs-instances-to-create-the-master-and-worker-nodes-of-an-ack-cluster?utm_content=g_1000230851&spm=5176.20966629.toubu.3.f2991ddcpxxvD1#title-084-lfh-8go
- https://etcd.io/docs/v3.4/op-guide/clustering/
- https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
- https://www.cybertec-postgresql.com/en/introduction-and-how-to-etcd-clusters-for-patroni/
- https://www.modb.pro/db/190000
- https://www.cnblogs.com/breg/p/16553555.html
- https://cloud.tencent.com/developer/article/1893782
- https://juejin.cn/post/7030740701260316702